Der erste Schritt des ICP-Algorithmus verfolgt das Ziel, Punktpaare
zu ermitteln. Für jeden Punkt der Menge ![]() muss der nächste Punkt in
der Menge
muss der nächste Punkt in
der Menge ![]() bestimmt werden. Abbildung 3.2 zeigt zwei
Scans des Flurs im FhG-AIS Gebäude C2, wobei der zweite Scan 2 Meter
,,hinter`` dem ersten liegt. Streng genommen liegt der zweite Scan im
ersten. Die Scanpunkte des ersten Scans sind schwarz, die des
zweiten blau dargestellt. Zu jedem Punkt des zweiten Scans wurde
der nächstgelegene im ersten Scan bestimmt und die Verbindung der beiden
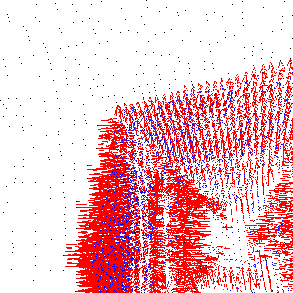
Punkte durch eine rote Linie gekennzeichnet. Die größere Punktdichte
im Überlappungsbereich lässt sich dadurch erklären, dass der zweite
Scan im ersten liegt. Auch müssen sich aus diesem Grund mehrere
Punkte des zweiten Scans einen Punkt des ersten Scans als nächsten
Punkt teilen, wie die vergrößerten Ausschnitte in der Abbildung
zeigen.
bestimmt werden. Abbildung 3.2 zeigt zwei
Scans des Flurs im FhG-AIS Gebäude C2, wobei der zweite Scan 2 Meter
,,hinter`` dem ersten liegt. Streng genommen liegt der zweite Scan im
ersten. Die Scanpunkte des ersten Scans sind schwarz, die des
zweiten blau dargestellt. Zu jedem Punkt des zweiten Scans wurde
der nächstgelegene im ersten Scan bestimmt und die Verbindung der beiden
Punkte durch eine rote Linie gekennzeichnet. Die größere Punktdichte
im Überlappungsbereich lässt sich dadurch erklären, dass der zweite
Scan im ersten liegt. Auch müssen sich aus diesem Grund mehrere
Punkte des zweiten Scans einen Punkt des ersten Scans als nächsten
Punkt teilen, wie die vergrößerten Ausschnitte in der Abbildung
zeigen.
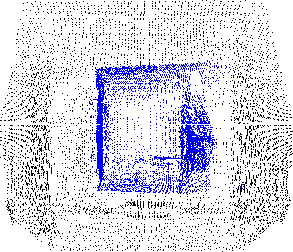
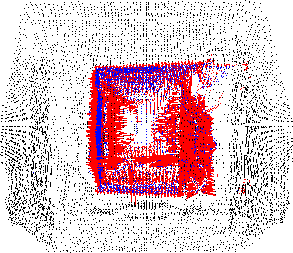

|
Die Performanzanalyse des ICP-Algorithmus hat gezeigt, dass seine Geschwindigkeit von der Suche nach den Punktpaaren dominiert wird. Dies ist der zeitaufwendigste Schritt des ICP-Algorithmus. Daher setzen alle Optimierungsversuche dort an. Zwei sich nicht ausschließende Strategien können hierbei verfolgt werden: